解析MySQL InnoDB存储引擎的事务实现机制,深入探讨ACID特性的具体实现方式、MVCC多版本并发控制原理、事务隔离级别设计以及并发事务可能产生的问题和解决方案。通过分析事务执行过程和读写视图机制,帮助理解数据库事务的核心原理。
事务四大特性(ACID)
- 原子性 Atomicity
- 一致性 Consistency
- 隔离性 Isolation
- 持久性 Durability
MySQL INNODB 分别是怎么实现这四个特性的
- Undo log 回滚日志实现原子性
Undo log 除了业务数据列外,还有 Trx Id(事务id)和 Roll Pointer(回滚指针)。Roll pointer 指向了该行的上一个历史版本记录(链表形式),触发回滚后可以恢复到事务开始之前。
一致性描述的是,事务开始前和完成后,数据都按照我们设计的方式去改变,而不会出现预想之外的情况。这个特性由其他三个特性共同来保证
MVCC 和锁实现隔离性,MVCC 会使用到 Undo log
快照读模式下,MVCC 在不同时机拍摄 read view (由隔离级别控制),这个 read view 定义了我们能够看到的_事务数据版本_,以此隔离不同事务间的可见性。
当前读模式下,通过 record lock 行锁 / gap lock 间隙锁锁住具体的记录或是记录间的间隙来实现事务隔离。
insert 操作,产生的 Undo log 只在事务回滚时需要,所以事务提交后会立刻丢弃;update 和 delete 操作,不仅回滚需要,MVCC 拍快照时也需要,所以提交后不会被立即丢弃。
- Redo log 重做日志、bin log 归档日志、两阶段提交实现持久性
数据更新时,更改_缓存页_的数据,并将更新记录写入 redo buffer 中;再进入两阶段提交过程:写 redo log (prepare) , bin log , redo log (commit)
Redo log 记录物理修改,负责恢复在事务提交后尚未落盘前宕机的数据丢失;bin log 记录逻辑语句,负责误删数据备份、主从同步。两阶段提交用于保证这两个日志的一致性。
事务隔离性中的四个隔离级别
- 读未提交
- 读已提交
- 可重复读
- 可串行化
后三个级别分别解决了,_脏读、不可重复读、幻读这几种事务并发问题。值得一提的是,在 INNODB 存储引擎中可重复读这一隔离级别已经能够解决幻读_问题。
INNODB 可重复读级别如何解决幻读问题
INNODB 用 MVCC 机制来解决_快照读中的幻读问题;用临键锁来解决当前读_中的幻读问题。
事务并发问题在生产中会造成的危害
除了幻读部分,以下提到的隔离性都为“快照隔离”,而非“串行化隔离”,for update是可以解决绝大部分的事务并发问题的,但其效率不佳,不到非用不可的地步我们不使用。
脏读
假设银行转账系统,账户初始金额 0 元,用户A 向用户B 转账,执行语句 update account set balance = balance + 100 where id = 1007,但其尚未提交;用户B 打开手机APP查询余额 select balance from account where id = 1007,读取到了转账事务中未提交的更新,发生了脏读,APP上显示当前余额为 100 元;此时系统服务出现异常,转账事务被迫终止回滚;用户B 再刷新APP显示余额为 0 元。
如果其他事务中,以该查询的返回结果为条件进行下一步的业务逻辑判断,后果将更加严重。比方说,恰好这时定时脚本将月流水不少于 100 元的用户识别为 vip 客户入库,那么数据库中可能出现一个月流水为 0 的 vip 客户。
不可重复读
脏读的危害比较容易想象,但不可重复读和幻读的危害大家可能就不太熟悉。
假设某银行客户福利系统,要求到结算日零点,当前余额为十元的为黄金vip客户,银行会奖励一箱卷纸;当前余额为一百元的为卓越vip客户,银行会奖励一台大彩电。事务开始,执行查询语句 select id from account where balance >= 10 and balance < 100 和 select id from account where balance >= 100,所匹配客户执行卷纸发放逻辑和大彩电发放逻辑。但如果在这两次查询执行过程中间,余额为 99 元的用户C 向自己的账户转入了 1 元,那么他将同时获得卷纸和大彩电!(搁这卡bug呢)就在同一时刻,另一余额为 100 元用户D,淘宝购物消费了 1 元,那么他既没有获得卷纸也没有获得彩电。
幻读
相同的福利系统,在卷纸查询和彩电查询中间,用户E 与用户F 分别存入 50 元和 100 元,则用户E 没有卷纸,而用户F 获得了彩电。
SELECT 执行过程
- 连接数据库
- 查询权限并缓存(本链接有效)
- 查询缓存
- 分析器,进行语法、词法分析
- 优化器,选索引,选join表顺序,制定查询计划
- 执行器,调用存储引擎,执行语句,如果选的是二级索引,取满足条件的第一行,回表查数据,放入结果集,继续取满足条件的第二行,循环执行。如果没走索引,就没有回表这一步了。
UPDATE 执行过程
- 将数据读入 InnoDB buffer pool,并对相关记录加独占锁
- 将 undo 信息写入 undo 表空间的回滚段中(MVCC)
- 更改缓存页的数据,并将更新记录写入 redo buffer 中
- 写 redolog (prepare) , binlog , redolog (commit) ,返回结果给客户端,释放锁(两阶段提交)
- 后台 IO 线程根据需要择机将缓存中更新过的数据刷新写入到磁盘文件中(刷脏页)
MVCC 工作原理
- 事务启动时,会先申请一个事务id(transaction-id),事务更新数据时,会把这个id作为记录的版本号(row trx_id)
- 每条记录更新是会记录回滚日志(undo log),这样一条记录在系统中可以存在多个版本,也就是 MVCC。undo log 的行记录中,除了 trx_id 还有指向上个记录的指针,可以通过执行 undo log 把数据回退到上一版本
- 每个事务都拥有自己的一致性视图(read view),一致性读会根据trx_id和一致性视图来确定数据版本的可见性。
- 在可重复读级别下,视图的创建时间是事务启动时(注:当前读会更新这个视图)
- 在读提交级别下,视图的创建时间是每条SQL开始执行时
- 读未提交级别下,总是返回最新的值
- 串行化级别下,通过加锁来避免并发访问
对于可重复读,查询只承认在事务启动之前就已经提交完成的数据。
对于读提交,查询只承认语句启动之前就已经提交完成的数据。
MVCC 在 InnoDB 中的实现
InnoDB 为每个事务构造了一个数组,保存这个事务启动的瞬间,活跃的事务ID**(已启动,未提交)**
事务ID 里的 最小值 记作_低水位_,最大值+1 记作_高水位_
这个数组和高低水位,构成了当前事务的一致性视图
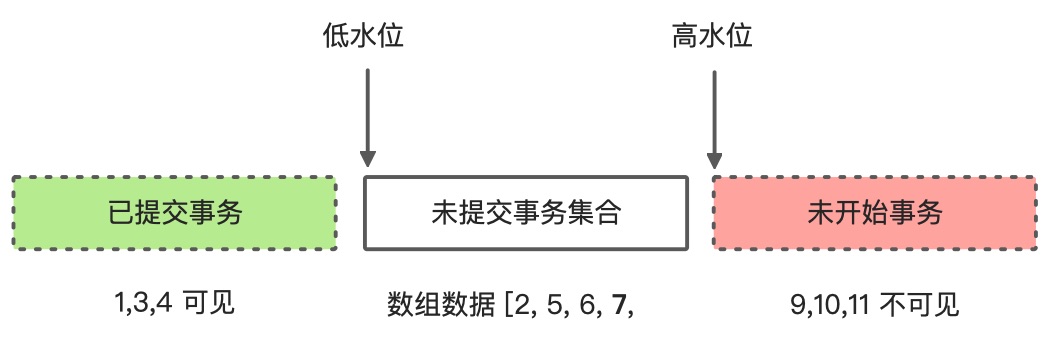
数据版本可见性分析
如果落在绿色部分,则可见;如果在红色部分,不可见;如果在白色部分,看他是否在数组里,在就不可见(2, 5, 6, 8),否则可见(3, 4),另外自己的版本可见(7)。
即:
- 版本未提交,不可见
- 版本在视图创建后提交,不可见
- 版本在视图创建前提交,可见
- 版本是当前事务的,可见