本文分析MySQL查询执行的各种访问类型,从最高效的const主键查询到全表扫描,详细介绍了索引查询策略、组合索引使用原则以及查询性能优化方法。通过具体的SQL示例和执行计划分析,帮助理解MySQL如何选择最优的查询路径。
概念
MySQL执行查询语句的方式称之为_访问类型(access type)或者_访问方法
具体分类
const
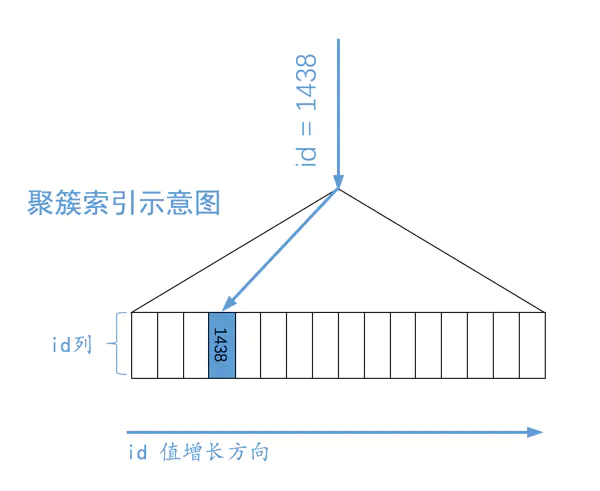
通过主键列来定位一条记录,比如:
SELECT * FROM table WHERE id = 1438;
MySQL 会直接利用主键值在聚簇索引中定位对应的记录
通过唯一索引列来定位一条记录,比如:
SELECT * FROM table_name WHERE key2 = 3841;
先利用非聚簇索引找到对应的主键值,再回表查询,进行主键索引的定位。
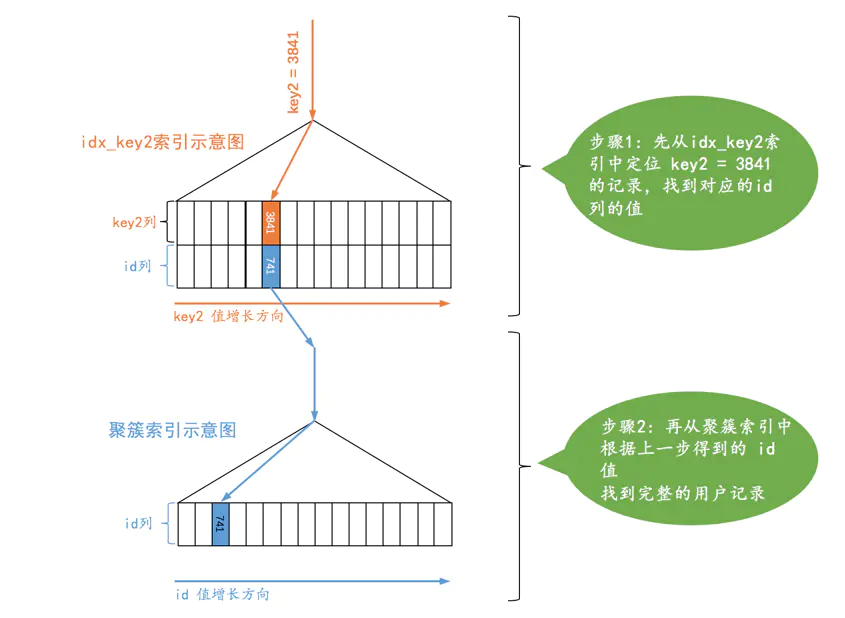
总之,是通过一个常量去索引中直接定位唯一对应的一行记录。
为什么会快呢?
因为这两种索引就是按其字段值的大小顺序组织的一棵 B+ 树,当我们有确定的常量值需要检索时,非常快。时间复杂度是 (m/2)*O( logm (n) ) ==推导==> O( log (n) ),但时间复杂度不是重点,B+ 树的主要优势是对磁盘 IO 的优化。
唯一索引有一种特例,(MySQL允许存储多行唯一索引为null的记录)
> explain select * from sql_test where uniq is null;
+----+-------------+----------+------------+------+---------------+-----+---------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | filtered | Extra |
+----+-------------+----------+------------+------+---------------+-----+---------+-------+----------+-----------------------+
| 1 | SIMPLE | sql_test | <null> | ref | q_k | q_k | 5 | const | 100.0 | Using index condition |
+----+-------------+----------+------------+------+---------------+-----+---------+-------+----------+-----------------------+
由于上述语句可能访问到多条数据,所以不能使用 const 的访问方法执行,而走的是 **ref **,即使当前表中只有一个唯一索引列为 null 的行。(可以查看 explain 语句的 type 字段)
ref
对普通二级索引与常数进行等值比较,比如:
SELECT * FROM table_name WHERE key1 = ‘abc’;
普通二级索引很可能会对应多个 ID 列,他们在该非聚簇索引中是连续的,通过查出的一系列 ID ,回表查询,进行主键索引的定位。
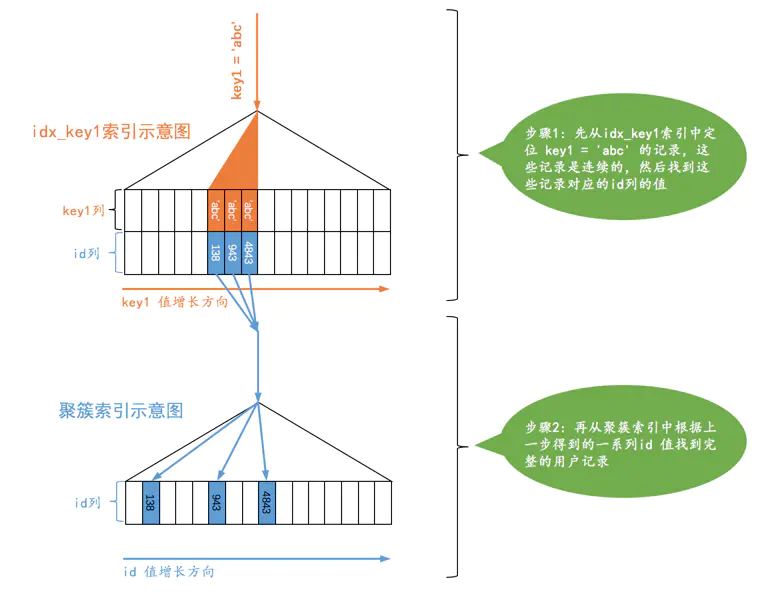
对于组合索引(包含多个索引列的二级索引)来说,只要是 _**最左边的连续索引列 **_是与常数的等值比较就会采用 ref 的访问方法,例如以下查询:
ALTER TABLE table_name add index(k1, k2, k3);
SELECT * FROM table_name WHERE k1 = 'zhou';
SELECT * FROM table_name WHERE k1 = 'zhou' AND k2 = 53;
SELECT * FROM single_table WHERE k1 = 'zhou' AND k2 = 53 AND k3 = 'shenzhen';
//但如果最左边的连续索引列并不全部是等值比较的话,它的访问类型就不是ref了,就是range了,比方说这样:
SELECT * FROM single_table WHERE k1 = 'zhou' AND k2 > 53;
ref_or_null
有时候我们不仅想找出某个二级索引列的值等于某个常数的记录,还想把该列的值为NULL的记录也找出来,就像下边这个查询:
SELECT * FROM table_name WHERE key1 = 'abc' OR key1 IS NULL;
当使用二级索引而不是全表扫描的方式执行该查询时,这种类型的查询使用的访问类型就称为 ref_or_null,这个访问类型的执行过程如下:
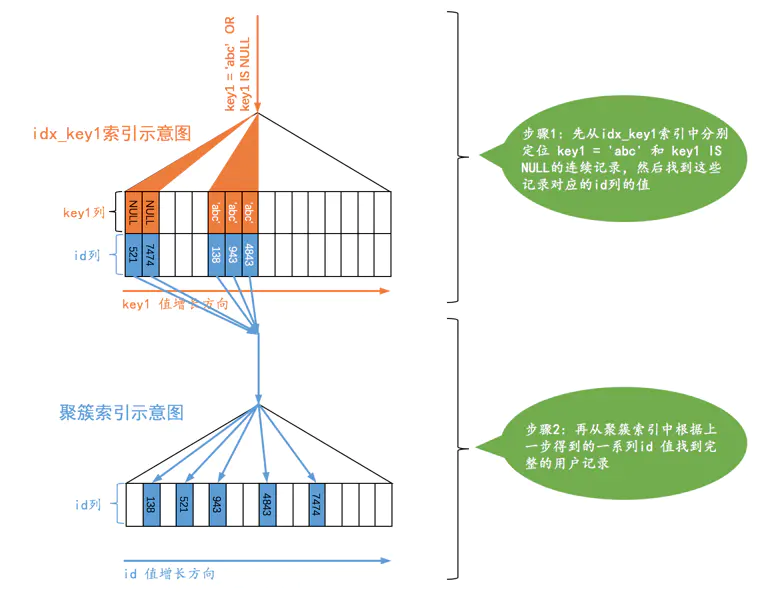
个人感觉和 ref 的过程很像,效率也差不多
range
SELECT * FROM table_name WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
- key2的值是1438
- key2的值是6328
- key2的值在38和79之间
这种利用索引进行范围匹配的访问类型称之为:range。
> explain select * from sql_test where name = 'zhou' and age > 2 ;
+----+-------------+----------+------------+-------+---------------+-----------+---------+--------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+-----------+---------+--------+------+----------+--------------------------+
| 1 | SIMPLE | sql_test | <null> | range | union_idx | union_idx | 1028 | <null> | 1 | 100.0 | Using where; Using index |
+----+-------------+----------+------------+-------+---------------+-----------+---------+--------+------+----------+--------------------------+
> explain select * from sql_test where name IN ('zhou', 'lu') and age = 2 ;
+----+-------------+----------+------------+-------+---------------+-----------+---------+--------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+-----------+---------+--------+------+----------+--------------------------+
| 1 | SIMPLE | sql_test | <null> | range | union_idx | union_idx | 1028 | <null> | 2 | 100.0 | Using where; Using index |
+----+-------------+----------+------------+-------+---------------+-----------+---------+--------+------+----------+--------------------------+
可见 IN 和 > 都属于范围查询。
这种情形下,使用到了组合索引的最左索引列,即使不一定能全然匹配组合索引中的所有的列(最左匹配原则),但是我们仍然能够在匹配完之后,再次过滤剩余条件。
index
SELECT key1, key2, key3 FROM table_name WHERE key2 = 'abc';
由于 key2 并不是联合索引 union_idx 的最左索引列,所以我们无法使用 ref 或者 range 访问方法来执行这个语句。
形象地说,就是全索引表扫描。
但是这个查询符合下边这两个条件:
- 它的查询列表只有3个列:key1, key2, key3,而索引 union_idx 又包含这三个列。
- 搜索条件中只有 key2 列。这个列也包含在索引 union_idx 中。
也就是说我们可以直接通过遍历 union_idx 索引的叶子节点的记录来比较 key2 = ‘abc’ 这个条件是否成立,把匹配成功的二级索引记录的 key1, key2, key3 列的值直接加到结果集中就行了。由于二级索引记录比聚簇索记录小的多(聚簇索引记录要存储所有用户定义的列以及所谓的隐藏列,而二级索引记录只需要存放索引列和主键),而且这个过程也不用进行回表操作,(这种查询需求和二级索引覆盖数据一致的操作叫做_覆盖索引_)所以遍历二级索引比直接遍历聚簇索引的成本要小很多,设计MySQL的大叔就把这种采用遍历二级索引记录的执行方式称之为:index。
索引题:当有个表有 A, B, C 三个字段,业务中的查询条件需要用到 AB, BC, AC ,那么我们应该如何建立索引?
我理解这里有两种选择:①建立 AB、BC、AC 三个二级索引 ②建立 ABC、BC 两个二级索引
- 每种查询条件都能通过匹配的索引进行,查询效率最好。但插入效率稍低一些(插入时需要依次更新一个主键索引和三个二级索引),且占用更多空间。
- 条件AB匹配索引"ABC",条件BC匹配索引"BC";条件AC先匹配索引"ABC"中的列"A",在索引中找到所有符合条件"A"的行,再在其中遍历找到符合条件"C"的行作为结果集。这种方式条件 AB、BC 的查找效率与方式①相同,条件 AC 稍慢一点(访问类型依然为 ref,只是 ref 项比 条件AB 少一个 const),但是优化了插入效率、节省了空间。
all
最直接的查询执行方式就是全表扫描,对于 InnoDB 表来说也就是直接扫描聚簇索引,这种方式叫做:all。
访问效率
system > const > eq_ref (多表) > ref > range > index > all